9.2.-JDBC: Básico
9.2. Acceso a bases de datos con Kotlin usando JDBC¶
Resumen
En este tema se trabaja el acceso a bases de datos a bajo nivel usando JDBC desde Kotlin. Veremos cómo preparar una tabla, añadir el driver, construir una URL JDBC, abrir una conexión, ejecutar consultas y usar un pool de conexiones con HikariCP.
JDBC es una API de bajo nivel. Esto significa que nos obliga a controlar detalles que otras herramientas esconden: conexión, sentencia, parámetros, resultados y cierre de recursos. Precisamente por eso es una buena forma de aprender qué ocurre realmente cuando una aplicación consulta una base de datos.
Directamente relacionado con el RA9 del módulo de Programación, este tema refuerza la programación de conexiones con bases de datos y la recuperación de información almacenada.
| Código | Descripción |
|---|---|
| RA9 | Gestiona información almacenada en bases de datos manteniendo la integridad y consistencia de los datos. |
| CE a | Se han identificado las características y métodos de acceso a sistemas gestores de bases de datos. |
| CE b | Se han programado conexiones con bases de datos. |
| CE d | Se han creado programas para recuperar y mostrar información almacenada en bases de datos. |
1. Qué vamos a aprender¶
En este punto trabajaremos sobre:
- Qué es JDBC y cómo se usa desde Kotlin.
- Qué papel tiene el driver JDBC.
- Cómo se construye una URL JDBC.
- Cómo establecer una conexión.
- Cómo ejecutar consultas SQL y leer un
ResultSet. - Qué es un pool de conexiones.
- Por qué existen abstracciones sobre JDBC.
2. Qué es JDBC¶
JDBC significa Java Database Connectivity. Es una API estándar del mundo Java que permite interactuar con bases de datos relacionales.
Desde Kotlin podemos usar JDBC porque Kotlin se ejecuta sobre la JVM y puede utilizar bibliotecas Java. Esto no significa que Kotlin incluya una base de datos, sino que puede trabajar con la API JDBC y con el driver correspondiente al SGBDR que se esté usando.
Un flujo básico con JDBC tiene esta forma:
Idea clave
JDBC define una forma común de trabajar con bases de datos, pero cada gestor necesita su driver: PostgreSQL, MySQL, MariaDB, H2, SQLite, etc.
3. Preparar una tabla¶
Para practicar necesitamos una tabla sencilla. En este ejemplo usaremos PostgreSQL, aunque el mismo flujo puede adaptarse a otros gestores.
Lectura del ejemplo:
userses la tabla donde guardaremos usuarios.ides la clave primaria.SERIALgenera un identificador incremental en PostgreSQL.nameguarda texto con un máximo de 20 caracteres.NOT NULLimpide insertar usuarios sin nombre.
Insertamos algunos datos de prueba:
Una consulta de comprobación:
Salida esperada:
Para clase
Antes de escribir código Kotlin, conviene comprobar la tabla desde el cliente SQL del gestor. Así separamos dos problemas: si la tabla no funciona en SQL, el error no está en Kotlin.
4. Añadir el driver JDBC¶
Para que JDBC pueda hablar con PostgreSQL necesitamos añadir el driver como dependencia del proyecto. En Gradle Kotlin DSL sería:
Lectura del ejemplo:
implementation(...)añade una dependencia al proyecto.org.postgresql:postgresqlidentifica el driver JDBC de PostgreSQL.- La versión puede cambiar con el tiempo según el proyecto.
- Si se usa MySQL, H2 u otro gestor, el driver será distinto.
Driver correcto
Si el driver no está en el classpath, la aplicación no podrá abrir la conexión aunque la URL, el usuario y la contraseña sean correctos.
5. URL JDBC¶
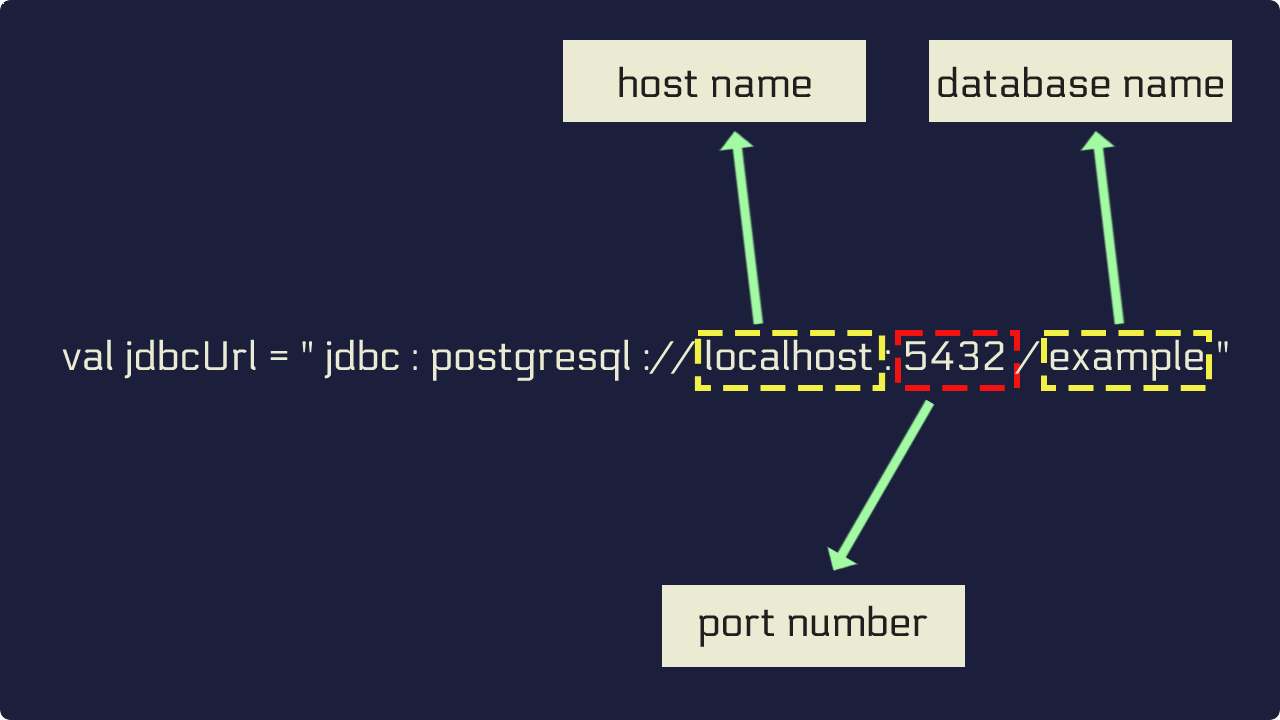
Una URL JDBC indica a qué base de datos queremos conectarnos. Para PostgreSQL puede tener esta forma:
La URL se puede leer así:
| Parte | Valor | Significado |
|---|---|---|
| Protocolo | jdbc:postgresql |
Usa JDBC con PostgreSQL. |
| Host | localhost |
Servidor donde está la base de datos. |
| Puerto | 5432 |
Puerto habitual de PostgreSQL. |
| Base de datos | example |
Nombre de la base de datos. |
6. Establecer una conexión¶
Para abrir una conexión usamos DriverManager.getConnection, pasando la URL, el usuario y la contraseña.
import java.sql.DriverManager
import java.sql.SQLException
fun main() {
val jdbcUrl = "jdbc:postgresql://localhost:5432/example"
val username = "postgres"
val password = "postgres"
try {
DriverManager.getConnection(jdbcUrl, username, password).use { connection ->
println("Conexión válida: ${connection.isValid(2)}")
}
} catch (e: SQLException) {
println("No se ha podido conectar: ${e.message}")
}
}
Lectura del ejemplo:
jdbcUrlindica la base de datos de destino.usernameypasswordson las credenciales.getConnectionintenta abrir la conexión.usecierra la conexión al terminar el bloque.isValid(2)comprueba si la conexión responde en 2 segundos.catchcaptura errores de JDBC medianteSQLException.
En ejemplos antiguos puede aparecer Class.forName("org.postgresql.Driver"). En proyectos actuales, si el driver está bien añadido como dependencia, normalmente se carga automáticamente.
Busca el ejemplo ConexionValida y estudialo/ejecutalo.
7. Crear una clase modelo¶
Antes de leer datos, conviene definir cómo queremos representarlos en Kotlin:
Esta clase representa una fila de la tabla users, pero no es la tabla. La tabla vive en la base de datos; el objeto User vive en memoria durante la ejecución del programa.
Busca el ejemplo MapeoFilaAObjeto y estudialo/ejecutalo.
8. Ejecutar una consulta SQL¶
Para ejecutar un SELECT con JDBC necesitamos:
- Abrir una conexión.
- Preparar una consulta.
- Ejecutarla con
executeQuery(). - Recorrer el
ResultSet. - Mapear cada fila a un objeto Kotlin.
- Cerrar recursos.
import java.sql.DriverManager
import java.sql.SQLException
data class User(val id: Int, val name: String)
fun main() {
val jdbcUrl = "jdbc:postgresql://localhost:5432/example"
val username = "postgres"
val password = "postgres"
try {
DriverManager.getConnection(jdbcUrl, username, password).use { connection ->
val sql = "SELECT id, name FROM users ORDER BY id"
connection.prepareStatement(sql).use { statement ->
statement.executeQuery().use { resultSet ->
val users = mutableListOf<User>()
while (resultSet.next()) {
val id = resultSet.getInt("id")
val name = resultSet.getString("name")
users.add(User(id, name))
}
println(users)
}
}
}
} catch (e: SQLException) {
println("Error al consultar usuarios: ${e.message}")
}
}
Lectura del ejemplo:
SELECT id, name FROM users ORDER BY idrecupera usuarios ordenados.prepareStatement(sql)prepara la consulta.executeQuery()devuelve unResultSet.resultSet.next()avanza fila a fila.getInt("id")lee la columnaidcomo entero.getString("name")lee la columnanamecomo texto.users.add(User(id, name))transforma la fila en un objeto.println(users)muestra la lista final.
Salida esperada:
Busca el ejemplo SelectBasico y estudialo/ejecutalo.
Por qué usamos PreparedStatement
Aunque esta consulta no tiene parámetros, usamos prepareStatement para mantener el mismo patrón que utilizaremos en consultas parametrizadas. Así evitamos alternar entre estilos y reducimos errores.
9. Pool de conexiones¶
Abrir una conexión a la base de datos es una operación costosa. Si una aplicación de servidor abre una conexión nueva por cada petición y la destruye al terminar, desperdicia recursos y puede saturar el SGBDR.
Un pool de conexiones mantiene varias conexiones abiertas y listas para reutilizarse. La aplicación pide una conexión al pool, la usa y la devuelve.
Busca el ejemplo PoolHikariBasico y estudialo/ejecutalo.
La biblioteca HikariCP es una opción muy utilizada para gestionar pools de conexiones en aplicaciones JVM.
10. HikariCP¶
Primero añadimos la dependencia:
Después configuramos el DataSource:
import com.zaxxer.hikari.HikariDataSource
fun crearDataSource(): HikariDataSource {
return HikariDataSource().apply {
jdbcUrl = "jdbc:postgresql://localhost:5432/example"
username = "postgres"
password = "postgres"
maximumPoolSize = 10
}
}
Lectura del ejemplo:
HikariDataSourcerepresenta el pool.jdbcUrl,usernameypasswordconfiguran el acceso.maximumPoolSize = 10limita el número máximo de conexiones.apply { ... }permite configurar el objeto de forma compacta.
Ahora usamos el DataSource para consultar:
fun obtenerUsuarios(dataSource: HikariDataSource): List<User> {
val sql = "SELECT id, name FROM users ORDER BY id"
val users = mutableListOf<User>()
dataSource.connection.use { connection ->
connection.prepareStatement(sql).use { statement ->
statement.executeQuery().use { resultSet ->
while (resultSet.next()) {
users.add(
User(
id = resultSet.getInt("id"),
name = resultSet.getString("name")
)
)
}
}
}
}
return users
}
La diferencia respecto a DriverManager es que ahora la conexión viene del pool. Al salir de use, la conexión se devuelve al pool y queda disponible para otra operación.
No confundir cerrar con destruir
Al usar un pool, cerrar una conexión normalmente significa devolverla al pool, no destruir la conexión física con el SGBDR.
11. Por qué existen abstracciones sobre JDBC¶
JDBC muestra el mecanismo real, pero también exige mucho código repetitivo:
- Abrir y cerrar conexiones.
- Preparar sentencias.
- Asignar parámetros.
- Recorrer
ResultSet. - Mapear filas a objetos.
- Gestionar excepciones.
Por eso existen herramientas de mayor nivel:
- JDBI: capa ligera sobre JDBC.
- Hibernate/JPA: ORM y estándar de persistencia.
- Exposed: biblioteca Kotlin para trabajar con SQL y DAO.
- Spring Data: repositorios y abstracción en aplicaciones Spring.
Estas herramientas no sustituyen la comprensión de JDBC. La mayoría se apoyan en JDBC o en conceptos equivalentes. Entender JDBC ayuda a depurar problemas cuando una abstracción falla o genera consultas inesperadas.
12. Conclusiones¶
- JDBC permite acceder a bases de datos relacionales desde Kotlin/JVM.
- Cada SGBDR necesita su driver JDBC.
- La URL JDBC identifica gestor, servidor, puerto y base de datos.
Connection,PreparedStatementyResultSetdeben cerrarse correctamente.ResultSetse recorre fila a fila y se transforma en objetos Kotlin.- Un pool de conexiones evita abrir conexiones físicas continuamente.
- HikariCP es una biblioteca habitual para gestionar conexiones reutilizables.
- Las abstracciones sobre JDBC reducen código, pero no eliminan la necesidad de entender lo que ocurre por debajo.
La idea clave es que JDBC enseña el recorrido completo entre la aplicación y la base de datos. Aunque más adelante usemos ORM o repositorios, saber qué ocurre en este nivel ayuda a escribir aplicaciones más seguras, eficientes y mantenibles.